custom table component
面试要求实现table + pagination + search这些功能,先看一下思路。先不考虑nextjs的server components,都默认是client components。
思路
我不建议一上来就写代码。
Senior 的做法是先说设计思路。
第一步:确认是前端分页还是服务端分页
我会先问:
数据量大概是多少?是前端分页还是后端分页?
What's the approximate size of the data we are dealing with?
Should the pagination be handled on the frontend or the backend?
因为这是两个完全不同的实现。
前端分页
例如:
xxxxxxxxxxconst users = [ ]100 条数据已经全部拿到。
前端负责:
xxxxxxxxxxsearchfilterpagination数据流:
xxxxxxxxxxallData ↓search ↓filteredData ↓pagination ↓pageData服务端分页
真实项目更常见:
xxxxxxxxxx?page=1&pageSize=10&search=tom后端返回:
xxxxxxxxxx{ "items": [], "total": 523}此时:
xxxxxxxxxxsearchpagination都需要重新请求 API。
第二步:拆组件
不要全部写在一个组件。
我会这样拆:
xxxxxxxxxxPage ├─ SearchInput ├─ Table └─ Pagination职责:
xxxxxxxxxxSearchInput负责输入Table负责展示Pagination负责翻页Page负责状态管理
第三步:状态设计
如果是前端分页:
xxxxxxxxxxconst [search, setSearch] = useState("");const [currentPage, setCurrentPage] = useState(1);const pageSize = 10;只有两个状态:
xxxxxxxxxxsearchcurrentPage不要存:
xxxxxxxxxxconst [filteredData, setFilteredData]不要存:
xxxxxxxxxxconst [pageData, setPageData]因为它们都是:
xxxxxxxxxxderived state可以计算出来。
第四步:数据流设计
先过滤:
xxxxxxxxxxconst filteredData = useMemo(() => { }, [data, search]);再分页:
xxxxxxxxxxconst pageData = useMemo(() => { }, [filteredData, currentPage]);面试时可以直接说:
xxxxxxxxxxSearch -> Filter -> Pagination而不是:
xxxxxxxxxxPagination -> Search因为用户希望:
xxxxxxxxxx先搜索再分页例如:
xxxxxxxxxx100条数据搜索 john得到 8 条分页显示 8 条而不是:
xxxxxxxxxx第一页10条再搜索结果错误
第五步:搜索和分页联动
这里特别容易考。
当用户搜索:
xxxxxxxxxxsetSearch(value);必须:
xxxxxxxxxxsetCurrentPage(1);否则:
xxxxxxxxxx当前在第 8 页搜索后只剩 1 页页面空白这是经典 Bug。
面试官特别喜欢问。
第六步:Pagination 设计
我会这样设计:
xxxxxxxxxx<Pagination currentPage={currentPage} totalPages={totalPages} onPageChange={setCurrentPage}/>组件只负责:
xxxxxxxxxxPrevious1234Next不要让 Pagination 知道:
xxxxxxxxxxsearchtableapi
第七步:性能优化
如果面试官继续追问:
数据量 5000 条怎么办?
我会回答:
xxxxxxxxxxuseMemo避免每次 render 都重新 filter。
如果:
xxxxxxxxxx50000+我会说:
xxxxxxxxxx服务端分页或者:
xxxxxxxxxxvirtualization例如:
- react-window
- TanStack Virtual
面试口语版(中文)
如果让我实现 Table、Search 和 Pagination,我会先确认是前端分页还是服务端分页。
对于前端分页,我会维护 search 和 currentPage 两个状态。数据流是先根据 search 过滤数据,再根据 currentPage 计算当前页的数据。
Table 只负责展示数据,Pagination 只负责切换页码,页面组件负责管理状态。
另外我会注意搜索时重置页码到第一页,避免搜索结果变少后出现空白页的问题。
如果数据量较大,我会使用 useMemo 优化过滤计算;如果数据量非常大,则考虑服务端分页或虚拟列表方案。
I would first clarify whether the requirement is client-side pagination or server-side pagination.
For client-side pagination, I would keep only two pieces of state: the search keyword and the current page. The data flow would be search filtering first, then pagination on the filtered result.
The Table component is responsible for rendering data, while the Pagination component only handles page navigation. State management stays in the parent component.
I would also reset the page number to page one whenever the search keyword changes to avoid empty pages.
For larger datasets, I would use memoization to optimize filtering, and for very large datasets I would switch to server-side pagination or list virtualization.
实现client side pagination
如果是面试手写,我会遵循一个原则:
xxxxxxxxxx先能跑再优化最后组件拆分很多候选人一上来就写:
xxxxxxxxxxSearchInputTablePaginationhooksutils结果 40 分钟过去了还没跑起来。
面试时更推荐:
xxxxxxxxxx一个组件先实现功能↓再拆组件↓再优化第一步:定义数据
假设有这样的数据:
xxxxxxxxxxconst users = [ { id: 1, name: "Tom", email: "tom@test.com" }, { id: 2, name: "Jerry", email: "jerry@test.com" }, { id: 3, name: "Alice", email: "alice@test.com" }, ];
第二步:状态
只存真正需要的状态
xxxxxxxxxxconst [search, setSearch] = useState("");const [currentPage, setCurrentPage] = useState(1);const pageSize = 5;不要存:
xxxxxxxxxxfilteredDatapageData因为都能计算出来。
第三步:过滤数据
xxxxxxxxxxconst filteredData = useMemo(() => { return users.filter((user) => user.name .toLowerCase() .includes(search.toLowerCase()) );}, [search]);
第四步:计算总页数
xxxxxxxxxxconst totalPages = Math.ceil( filteredData.length / pageSize);
第五步:计算当前页数据
xxxxxxxxxxconst pageData = useMemo(() => { const start = (currentPage - 1) * pageSize; return filteredData.slice( start, start + pageSize );}, [filteredData, currentPage]);
第六步:搜索时重置页码
这是面试高频坑。
xxxxxxxxxxfunction handleSearch( e: React.ChangeEvent<HTMLInputElement>) { setSearch(e.target.value); setCurrentPage(1);}
第七步:完整实现
xxxxxxxxxx"use client";import { useMemo, useState } from "react";const users = [ { id: 1, name: "Tom", email: "tom@test.com" }, { id: 2, name: "Jerry", email: "jerry@test.com" }, { id: 3, name: "Alice", email: "alice@test.com" }, { id: 4, name: "Bob", email: "bob@test.com" }, { id: 5, name: "John", email: "john@test.com" }, { id: 6, name: "Emma", email: "emma@test.com" }, { id: 7, name: "Mike", email: "mike@test.com" }, { id: 8, name: "Sarah", email: "sarah@test.com" }, { id: 9, name: "Chris", email: "chris@test.com" }, { id: 10, name: "Kevin", email: "kevin@test.com" }, { id: 11, name: "David", email: "david@test.com" },];export default function UserTable() { const [search, setSearch] = useState(""); const [currentPage, setCurrentPage] = useState(1); const pageSize = 5; const filteredData = useMemo(() => { return users.filter((user) => user.name .toLowerCase() .includes(search.toLowerCase()) ); }, [search]); const totalPages = Math.ceil( filteredData.length / pageSize ); const pageData = useMemo(() => { const start = (currentPage - 1) * pageSize; return filteredData.slice( start, start + pageSize ); }, [filteredData, currentPage]); function handleSearch( e: React.ChangeEvent<HTMLInputElement> ) { setSearch(e.target.value); setCurrentPage(1); } return ( <div className="space-y-4 p-6"> <input type="text" placeholder="Search users..." value={search} onChange={handleSearch} className=" w-full rounded border px-3 py-2 " /> <table className=" w-full border-collapse border " > <thead> <tr> <th className="border p-2">ID</th> <th className="border p-2">Name</th> <th className="border p-2">Email</th> </tr> </thead> <tbody> {pageData.map((user) => ( <tr key={user.id}> <td className="border p-2"> {user.id} </td> <td className="border p-2"> {user.name} </td> <td className="border p-2"> {user.email} </td> </tr> ))} </tbody> </table> <div className="flex gap-2"> <button disabled={currentPage === 1} onClick={() => setCurrentPage((p) => p - 1) } > Prev </button> <span> {currentPage} / {totalPages} </span> <button disabled={ currentPage === totalPages } onClick={() => setCurrentPage((p) => p + 1) } > Next </button> </div> </div> );}
CSS重点
我看到th和td上面,都设置了border,但是实际效果却border没有累加,还是1px,为什么?
这是因为table上加了border-collapse的样式,等于下面这个样式:
xxxxxxxxxxtable { border-collapse: collapse; }开启后,相邻单元格的边框不会叠加,浏览器只保留一条边框。
这个真的好用,我之前很多样式问题都能靠这个来解决。
优化
搜索需要加上防抖。
方案一:Debounced State(面试最喜欢)
维护两个状态:
xxxxxxxxxxconst [search, setSearch] = useState("");const [debouncedSearch, setDebouncedSearch] = useState("");监听 search:
xxxxxxxxxxuseEffect(() => { const timer = setTimeout(() => { setDebouncedSearch(search); }, 300); return () => { clearTimeout(timer); };}, [search]);过滤时,从监听search改为监听debouncedSearch:
xxxxxxxxxxconst filteredData = useMemo(() => { return users.filter((user) => user.name .toLowerCase() .includes( debouncedSearch.toLowerCase() ) );}, [users, debouncedSearch]);输入框内容不变:
xxxxxxxxxx<input value={search} onChange={handleSearch}/>执行过程:
xxxxxxxxxx输入:rrereareacreactsearch:连续更新debouncedSearch:300ms后只更新一次filter:只执行一次封装成 Hook(生产环境)
很多团队会写:
xxxxxxxxxxfunction useDebounce<T>( value: T, delay = 300) { const [debouncedValue, setDebouncedValue] = useState(value); useEffect(() => { const timer = setTimeout(() => { setDebouncedValue(value); }, delay); return () => clearTimeout(timer); }, [value, delay]); return debouncedValue;}使用:
xxxxxxxxxxconst [search, setSearch] = useState("");const debouncedSearch = useDebounce(search, 300);过滤:
xxxxxxxxxxconst filteredData = useMemo(() => { return users.filter((user) => user.name .toLowerCase() .includes( debouncedSearch.toLowerCase() ) );}, [users, debouncedSearch]);
React 18/19 更现代的方案
其实对于 Client Side Search,很多时候根本不需要 Debounce。
可以使用:
xxxxxxxxxxconst deferredSearch = useDeferredValue(search);过滤:
xxxxxxxxxxconst filteredData = useMemo(() => { return users.filter((user) => user.name .toLowerCase() .includes( deferredSearch.toLowerCase() ) );}, [users, deferredSearch]);区别:
Debounce
xxxxxxxxxx用户停止输入300ms才开始搜索useDeferredValue
xxxxxxxxxx立即更新输入框搜索延后执行用户体验通常更好。
对于 Client Side Search,如果过滤逻辑比较重,我会使用 Debounce 或 useDeferredValue 减少不必要的计算。对于 Server Side Search,我通常会结合 Debounce,避免用户输入过程中频繁发送网络请求。
English:
For client-side filtering, I usually use debounce or useDeferredValue when the filtering operation is expensive. For server-side search, I typically debounce the input to avoid sending unnecessary API requests while the user is still typing.
client side pagination 追问
通常下一步会问:
如果让我把 Table 抽成一个可复用组件呢?
这时候就可以开始第二阶段:
xxxxxxxxxx<Table<T>><Pagination /><SearchInput />甚至做成:
xxxxxxxxxx<DataTable data={users} columns={columns}/>这种类似于 TanStack Table 的设计。这个也是中高级 React 面试特别爱考的一步。
很好,这其实就是从:
xxxxxxxxxx能写业务↓能设计组件的分水岭了。
很多中级工程师能写出:
xxxxxxxxxx<UserTable />但是高级工程师会开始思考:
xxxxxxxxxx如果以后有:UsersTableProductsTableOrdersTableCategoriesTable怎么办?总不能复制 4 份 Table 吧。
第一步:抽象 Table
我们先看哪些东西会变化。
xxxxxxxxxx<table> <thead> <tr> <th>ID</th> <th>Name</th> <th>Email</th> </tr> </thead> <tbody> {users.map() } </tbody></table>变化的是:
xxxxxxxxxxcolumnsdata固定的是:
xxxxxxxxxxtable结构theadtbodytrtd所以我们抽:
xxxxxxxxxx<Table data={users} columns={columns}/>
第二步:设计 Columns
这是最经典的设计。
xxxxxxxxxxconst columns = [ { key: "id", title: "ID", }, { key: "name", title: "Name", }, { key: "email", title: "Email", },];然后 Table 自动渲染:
xxxxxxxxxx<thead> <tr> {columns.map() } </tr></thead>
第三步:支持自定义 Cell
面试官一定会问:
如果状态字段需要显示 Tag 怎么办?
例如:
xxxxxxxxxx{ id: 1, name: "Tom", status: "active"}不能直接:
xxxxxxxxxx<td>{row.status}</td>要支持:
xxxxxxxxxxconst columns = [ { key: "status", title: "Status", render: (value) => ( <Badge>{value}</Badge> ), },];类似:
xxxxxxxxxxTanStack TableAnt Design Table的设计。
第四步:TypeScript 泛型
这是高级面试必问。
定义:
xxxxxxxxxxtype Column<T> = { key: keyof T; title: string; render?: ( value: T[keyof T], row: T ) => React.ReactNode;};
keyof T:这是 TypeScript 的索引类型查询操作符,它会提取出类型T所有属性名(键)组成的联合类型。
- 作用:强制要求这一列对应的字段名,必须是数据源对象中真实存在的属性。防止手误拼错字段名。
value: T[keyof T]:当前单元格的值(对应字段的数据类型)。
row: T:当前行完整的数据对象,方便你根据同一行里的其他字段来决定怎么渲染当前单元格。
Table:
xxxxxxxxxxtype TableProps<T> = { data: T[]; columns: Column<T>[];};组件:
xxxxxxxxxxexport function Table<T>({ data, columns,}: TableProps<T>) { }这样:
xxxxxxxxxx<Table<User> data={users} columns={columns}/>自动推导类型。
注意:
render是一个函数,所以当有render时,直接执行即可。
xxxxxxxxxxtype Column<T> = { key: keyof T; title: string; render?: (value: T[keyof T], row: T) => React.ReactNode;};type TableProps<T> = { data: T[]; columns: Column<T>[];};export default function CustomTable<T>({ data, columns }: TableProps<T>) { return ( <table className="w-full border-collapse border"> <thead> <tr> {columns.map((col) => ( <th className="border p-2" key={String(col.key)}> {col.title} </th> ))} </tr> </thead> <tbody> {data.map((row, rowIndex) => ( <tr key={rowIndex}> {columns.map((col) => { const value = row[col.key]; return ( <td key={String(col.key)} className="border p-2"> {col.render ? col.render(value, row) : String(value)} </td> ); })} </tr> ))} </tbody> </table> );}这里的CustomTable组件,我使用的时候,需要传递T类型过来吗?
- 自动推导(最常用、最省心 ⭐️⭐️⭐️)
当你把带有明确类型定义的
data数组赋值给CustomTable的data属性时,TypeScript 会顺藤摸瓜,自动把data数组中元素的类型当做T传递进去。
- 显式手动传递(当你想强制约束时 ⭐️⭐️)
有时候你的
data可能是从后端接口异步拿到的,初始值是个空数组[],此时 TS 无法自动推导出T的类型。你就需要像调用泛型函数一样,在 JSX 标签上显式地写出<User>。
- 语法:
<组件名<类型> ... />xxxxxxxxxx// 💡 显式将 User 作为 T 传递进去<CustomTable<User>data={loadingData}columns={[{key: "name", // ✨ 这里会享受到完备的 User 属性提示title: "姓名",// render 里的 value 也会被精准识别为 string,row 被识别为 Userrender: (value, row) => <span>{value} ({row.age})</span>}]}/>
第五步:Pagination 抽出来
刚刚我们写:
xxxxxxxxxx<div> Prev 1 / 10 Next</div>抽成:
xxxxxxxxxx<Pagination currentPage={currentPage} totalPages={totalPages} onPageChange={setCurrentPage}/>职责:
xxxxxxxxxxPagination只负责页码不负责数据这是组件设计原则:
xxxxxxxxxx单一职责xxxxxxxxxxtype PaginationProps = { currentPage: number; totalPages: number; onPageChange: (page: number) => void;};export default function Pagination({ currentPage, totalPages, onPageChange,}: PaginationProps) { return ( <div className="flex items-center gap-4"> <button disabled={currentPage === 1} onClick={() => onPageChange(currentPage - 1)}> Previous </button> <span> {currentPage} / {totalPages} </span> <button disabled={currentPage === totalPages} onClick={() => onPageChange(currentPage + 1)}> Next </button> </div> );}
第六步:SearchInput 抽出来
xxxxxxxxxx<SearchInput value={search} onChange={setSearch}/>这样:
xxxxxxxxxxSearchInputTablePagination全部可复用。
xxxxxxxxxxtype SearchInputProps = { value: string; onChange: (value: string) => void;};export default function SearchInput({ value, onChange }: SearchInputProps) { return ( <input type="text" value={value} onChange={(e) => onChange(e.target.value)} placeholder="Search..." className="border py-2 px-4" /> );}
第七步:父组件组合
最终:
xxxxxxxxxx<UserPage>内部:
xxxxxxxxxx<SearchInput /><Table /><Pagination />状态全部在页面层。lift state up.
xxxxxxxxxxconst [search, setSearch] = useState("");const [currentPage, setCurrentPage] = useState(1);数据流:
xxxxxxxxxxsearch ↓filteredData ↓pageData ↓Tablexxxxxxxxxx"use client";import { useMemo, useState } from "react";import Pagination from "../components/client-side/table/pagination";import CustomTable, { type Column,} from "../components/client-side/table/table";import SearchInput from "../components/client-side/table/search-input";const PAGE_SIZE = 10;interface User { id: number; name: string; email: string; gender: string; country: string;}const users: User[] = [ { id: 1, name: "Vail", email: "vcleminson0@i2i.jp", gender: "Male", country: "Brazil", }, { id: 2, name: "Mylo", email: "mhollyman1@soup.io", gender: "Male", country: "Portugal", }, ];export default function ClientPage() { const [search, setSearch] = useState(""); const [currentPage, setCurrentPage] = useState(1); const filteredUsers = useMemo(() => { return users.filter((user) => user.name.toLowerCase().includes(search.toLowerCase()), ); }, [search]); const totalPages = Math.ceil(filteredUsers.length / PAGE_SIZE); const pageData = useMemo(() => { const start = (currentPage - 1) * PAGE_SIZE; return filteredUsers.slice(start, start + PAGE_SIZE); }, [filteredUsers, currentPage]); const handleSearch = (value: string) => { setSearch(value); setCurrentPage(1); }; const columns: Column<User>[] = [ { key: "id", title: "Id", }, { key: "name", title: "Name", }, { key: "email", title: "Email", }, { key: "gender", title: "Gender", render: (value) => ( <span className={value === "Male" ? "text-orange-900" : "text-pink-500"}> {value} </span> ), }, { key: "country", title: "Country", }, ]; return ( <div className="space-y-4 p-4"> <SearchInput value={search} onChange={handleSearch} /> <CustomTable data={pageData} columns={columns} /> <Pagination currentPage={currentPage} totalPages={totalPages} onPageChange={setCurrentPage} /> </div> );}效果:

面试官追问:还能继续优化吗?
这里才是真正的高级题。
你可以说:
方案1:抽 Hook
xxxxxxxxxxconst { pageData, currentPage, totalPages,} = usePagination()我会让 Hook 只负责分页状态和分页计算,不负责搜索和排序。Hook 接收数据和 pageSize,返回当前页数据、总页数以及分页操作方法。这样搜索、排序、过滤都可以在外部完成,分页 Hook 保持单一职责,也更容易复用。
xxxxxxxxxximport { useEffect, useMemo, useState } from "react";export default function usePagination<T>(data: T[], pageSize: number) { const [currentPage, setCurrentPage] = useState(1); const totalPages = Math.max(Math.ceil(data.length / pageSize), 1); // 避免搜索后,currentPage > totalPages的情况,强行固定到totalPages,也就是最后一页。或者这里可以固定到第一页。 useEffect(() => { if (currentPage > totalPages) { setCurrentPage(totalPages); } }, [currentPage, totalPages]); const pageData = useMemo(() => { const start = (currentPage - 1) * pageSize; return data.slice(start, start + pageSize); }, [data, currentPage, pageSize]); return { currentPage, totalPages, pageData, setCurrentPage, };}
方案2:DataTable
进一步组合:
xxxxxxxxxx<DataTable data={users} columns={columns}/>内部直接包含:
xxxxxxxxxxSearchPaginationTable类似 TanStack Table的设计思路。
Senior 面试口语版(中英双语)
如果只有一个表格,我会直接实现功能。但如果系统里有多个表格,例如用户、订单和商品列表,我会把 Table、Pagination 和 SearchInput 抽成独立组件。
Table 接收 data 和 columns,通过泛型保证类型安全。Pagination 只负责页码切换,不关心数据来源。SearchInput 只负责输入和事件通知。
页面组件负责状态管理和数据流控制,这样组件职责清晰,也更容易复用和测试。
If there is only one table, I would implement it directly. However, if the application contains multiple tables such as users, orders, and products, I would extract Table, Pagination, and SearchInput into reusable components.
The Table component would accept data and columns and use TypeScript generics for type safety. Pagination would only handle page navigation, while SearchInput would only manage user input.
The page component would own the state and control the data flow. This keeps responsibilities clear and makes the components easier to reuse and test.
client side pagination 追问
你刚刚设计的 Table,如何支持:
- Sorting
- Row Selection
- Column Visibility
- Server-side Pagination
- Server-side Search
并且不把 Table 组件搞成一个 2000 行的怪物组件?
这就是很多公司会考的 DataTable 架构设计题。
这一步就开始接近真正的 Senior 面试了。
因为现在的问题已经不是:
xxxxxxxxxx怎么写 Table而是:
xxxxxxxxxx怎么设计一个长期可维护的 DataTable
初级工程师的写法
很多人会这样写:
xxxxxxxxxx<DataTable data={data} columns={columns} searchable sortable selectable pagination rowExpandable columnVisibility stickyHeader .../>然后内部:
xxxxxxxxxxfunction DataTable() { // 2000行代码 // search // sort // pagination // selection // expansion // visibility // virtualization return }最后变成:
xxxxxxxxxxGod Component(上帝组件)没人敢改。
Senior 的第一原则
不要把所有逻辑塞进 Table。
Table 应该只负责:
xxxxxxxxxxRender即:
xxxxxxxxxx展示数据而不是:
xxxxxxxxxx搜索数据排序数据请求数据缓存数据
架构分层
我一般会拆成:
xxxxxxxxxxPage ↓Data Layer ↓Table UI Layer例如:
xxxxxxxxxx<UserPage />负责:
xxxxxxxxxxconst [search, setSearch] = useState("");const query = useUsers({ search, page, sort,});然后:
xxxxxxxxxx<DataTable data={query.data} columns={columns}/>Table 根本不知道:
xxxxxxxxxxAPIReact QuerySearchPagination这些东西。
Sorting 怎么设计?
很多人的第一反应:
xxxxxxxxxx<DataTable sortable />然后内部:
xxxxxxxxxxconst [sort, setSort] = useState()我一般不会这么做。
更推荐:
xxxxxxxxxxconst [sorting, setSorting] = useState<SortingState>([]);然后:
xxxxxxxxxx<DataTable sorting={sorting} onSortingChange={setSorting}/>这是 React 最经典的模式:
xxxxxxxxxxControlled Component类似:
xxxxxxxxxx<input value={value} onChange={setValue}/>
为什么?
因为以后可能:
xxxxxxxxxxURL同步LocalStorage同步Server同步如果状态藏在 Table 里面:
xxxxxxxxxx无法控制
Search 怎么设计?
同理:
不要:
xxxxxxxxxx<DataTable searchable/>而是:
xxxxxxxxxx<DataTableToolbar search={search} onSearchChange={setSearch}/>因为:
xxxxxxxxxxSearch 属于业务层不是 Table 层
Server Pagination 怎么设计?
很多候选人会这样写:
xxxxxxxxxx<DataTable fetchData={fetchUsers}/>我一般不喜欢。
因为:
xxxxxxxxxxTable 开始负责 API职责变重。
更推荐:
xxxxxxxxxxconst query = useUsers({ page, pageSize,});然后:
xxxxxxxxxx<DataTable data={query.items} total={query.total} page={page} onPageChange={setPage}/>这样:
xxxxxxxxxxData Fetching和Data Rendering彻底分离
Row Selection
不要:
xxxxxxxxxx<DataTable selectable />内部自己存:
xxxxxxxxxxselectedRows而是:
xxxxxxxxxxconst [selectedRows, setSelectedRows] = useState({});传进去:
xxxxxxxxxx<DataTable rowSelection={selectedRows} onRowSelectionChange={ setSelectedRows }/>和 TanStack Table 一模一样。
Column Visibility
不要:
xxxxxxxxxx<DataTable hiddenColumns={}/>而是:
xxxxxxxxxxconst [columnVisibility, setColumnVisibility] = useState({});然后:
xxxxxxxxxx<DataTable columnVisibility={ columnVisibility } onColumnVisibilityChange={ setColumnVisibility }/>
你会发现什么?
所有高级功能:
xxxxxxxxxxSortingPaginationSearchSelectionColumn Visibility都遵循同一个模式:
xxxxxxxxxxState Lift Up即:
xxxxxxxxxx状态在外部Table 只消费状态
最终架构
我实际项目更喜欢:
xxxxxxxxxxUserPage│├── DataTableToolbar│ ├── Search│ ├── Filters│ └── Export│├── DataTable│└── Pagination状态:
xxxxxxxxxxconst [search, setSearch] = useState("");const [sorting, setSorting] = useState([]);const [pagination, setPagination] = useState({ pageIndex: 0, pageSize: 10,});const [rowSelection, setRowSelection] = useState({});然后:
xxxxxxxxxx<DataTable data={data} columns={columns} sorting={sorting} onSortingChange={setSorting} pagination={pagination} onPaginationChange={ setPagination } rowSelection={rowSelection} onRowSelectionChange={ setRowSelection }/>
面试口语版(高级)
对于复杂表格,我不会把搜索、排序、分页和选择状态放在 Table 内部,而是采用受控组件模式,把状态提升到页面层管理。Table 只负责展示数据和触发事件。这样可以方便地与 URL、服务端查询、缓存以及权限系统集成,同时也能避免 Table 组件变成一个难以维护的大组件。
For complex tables, I prefer a controlled component approach. Instead of keeping sorting, pagination, filtering, and row selection state inside the table, I lift those states to the page level. The table is only responsible for rendering data and emitting events. This makes it easier to integrate with URLs, server-side queries, caching, and permission systems while keeping the table component maintainable and reusable.
实现server side pagination
当然可以,而且现在的 React + Next.js 项目里,Server Side Pagination(服务端分页)反而是主流方案。
如果面试官问:
你会实现 Server Side Pagination 吗?
你应该回答:
会。通常分页、搜索、排序条件都放在 URL 或状态中,然后将这些参数传递给后端 API,由数据库完成分页查询,只返回当前页的数据和总数。
最经典的流程
前端
xxxxxxxxxx?page=2&pageSize=10或者:
xxxxxxxxxx?page=2&pageSize=10&search=react&sort=name&order=ascAPI
xxxxxxxxxxGET /api/users?page=2&pageSize=10&search=react后端
SQL:
xxxxxxxxxxSELECT *FROM usersLIMIT 10OFFSET 10;同时查询:
xxxxxxxxxxSELECT COUNT(*)FROM users;返回
xxxxxxxxxx{ "items": [], "total": 523}前端计算页数
xxxxxxxxxxconst totalPages = Math.ceil( total / pageSize);
Next.js App Router 方案
这是目前比较高频的面试答案。
URL
xxxxxxxxxx/users?page=3page.tsx
xxxxxxxxxxexport default async function UsersPage({ searchParams,}: { searchParams: Promise<{ page?: string; }>;}) { const { page } = await searchParams; const currentPage = Number(page) || 1; const res = await fetch( `https://api.example.com/users?page=${currentPage}` ); const data = await res.json(); return ( <UserTable users={data.items} total={data.total} page={currentPage} /> );}这样:
xxxxxxxxxx?page=1?page=2?page=3都会触发新的 Server Render。
这是非常符合 Next.js 思维的。
Client Component 如何翻页?
xxxxxxxxxx"use client";const router = useRouter();function onPageChange(page: number) { router.push( `/users?page=${page}` );}用户点击:
xxxxxxxxxxNext变成:
xxxxxxxxxx/users?page=2然后:
xxxxxxxxxxServer Component重新获取数据重新渲染
面试官可能继续追问
为什么不用前端分页?
例如:
xxxxxxxxxx一次拉 10000 条前端 slice缺点:
网络浪费
xxxxxxxxxx10000条↓实际只展示10条首屏变慢
xxxxxxxxxx等待整个数据集返回内存占用
xxxxxxxxxx浏览器保存全部数据搜索不准确
例如:
xxxxxxxxxx第一页react第二页nextjs如果只在当前页搜索:
xxxxxxxxxx找不到 nextjs实际上数据存在其他页。
所以大数据场景应该:
xxxxxxxxxxSearchSortPagination全部交给服务端。
Senior 级别回答
如果我是面试官,我比较喜欢听到这种答案:
对于小数据集,我会使用 Client Side Pagination,减少请求次数。
对于中大型数据集,我会采用 Server Side Pagination,把分页、搜索和排序参数传递给后端,由数据库完成查询。
在 Next.js App Router 中,我通常会将分页状态放入 URL Search Params,使页面具备可分享、可刷新和 SEO 友好的特性,然后由 Server Components 根据 searchParams 获取对应页的数据。
这已经是一个比较完整且偏生产环境的回答了。
server side pagination完整实现
我给你一个 Next.js 16 + App Router + Server Side Pagination 的完整例子。
目录结构
xxxxxxxxxxapp├── users│ ├── page.tsx│ ├── user-table.tsx│ └── pagination.tsx1. Server Component
xxxxxxxxxx// app/users/page.tsximport UserTable from "./user-table";import Pagination from "./pagination";type User = { id: number; name: string; email: string;};type ApiResponse = { items: User[]; total: number;};const PAGE_SIZE = 10;export default async function UsersPage({ searchParams,}: { searchParams: Promise<{ page?: string; }>;}) { const params = await searchParams; const page = Number(params.page ?? 1); const res = await fetch( `https://api.example.com/users?page=${page}&pageSize=${PAGE_SIZE}`, { cache: "no-store", } ); const data: ApiResponse = await res.json(); const totalPages = Math.ceil( data.total / PAGE_SIZE ); return ( <div className="space-y-4"> <h1 className="text-2xl font-bold"> Users </h1> <UserTable users={data.items} /> <Pagination currentPage={page} totalPages={totalPages} /> </div> );}2. Table
xxxxxxxxxx// app/users/user-table.tsxtype User = { id: number; name: string; email: string;};export default function UserTable({ users,}: { users: User[];}) { return ( <table className="w-full border"> <thead> <tr> <th>ID</th> <th>Name</th> <th>Email</th> </tr> </thead> <tbody> {users.map((user) => ( <tr key={user.id}> <td>{user.id}</td> <td>{user.name}</td> <td>{user.email}</td> </tr> ))} </tbody> </table> );}3. Pagination
xxxxxxxxxx// app/users/pagination.tsx"use client";import { useRouter } from "next/navigation";type Props = { currentPage: number; totalPages: number;};export default function Pagination({ currentPage, totalPages,}: Props) { const router = useRouter(); function goToPage(page: number) { router.push( `/users?page=${page}` ); } return ( <div className="flex gap-4"> <button disabled={currentPage === 1} onClick={() => goToPage(currentPage - 1) } > Previous </button> <span> {currentPage} / {totalPages} </span> <button disabled={ currentPage === totalPages } onClick={() => goToPage(currentPage + 1) } > Next </button> </div> );}真实项目会怎么写?
上面的代码能跑,但还不够生产级。
真实项目通常会把:
xxxxxxxxxxpagesearchsortorderpageSize全部放进 URL。
例如:
xxxxxxxxxx/users?page=2&pageSize=20&search=react&sort=name&order=asc然后统一解析:
xxxxxxxxxxconst page = Number(searchParams.page ?? 1);const pageSize = Number(searchParams.pageSize ?? 10);const search = searchParams.search ?? "";const sort = searchParams.sort ?? "createdAt";const order = searchParams.order ?? "desc";然后请求:
xxxxxxxxxxawait fetch( `/api/users?` + new URLSearchParams({ page: String(page), pageSize: String(pageSize), search, sort, order, }));如果用 Prisma
后端通常长这样:
xxxxxxxxxxconst users = await prisma.user.findMany({ where: { name: { contains: search, }, }, orderBy: { [sort]: order, }, skip: (page - 1) * pageSize, take: pageSize, });总数:
xxxxxxxxxxconst total = await prisma.user.count({ where: { name: { contains: search, }, }, });返回:
xxxxxxxxxxreturn { items: users, total,};
面试加分点
如果面试官问:
为什么把分页状态放到 URL?
你可以回答:
中文:
- 支持刷新后保留状态
- 支持分享链接
- 支持浏览器前进后退
- Next.js Server Component 可以直接读取 searchParams
- SEO 和可访问性更好
English:
I usually keep pagination, filtering, and sorting state in URL search parameters because it makes the page shareable, bookmarkable, refresh-safe, and easier to integrate with Server Components in Next.js.
这个回答已经是 Senior Frontend 的水平了。
tanstack/table案例
一个参考案例
有一个很好的table案例,https://github.com/sadmann7/tablecn,如果不能直接使用,那么可以仿照写。这个案例也是使用tanstack/table来做的。代码在code文件夹里面,可以看到,还是非常复杂的。因为作者使用nextjs创建的项目,所以这个table是可以用在server component里面的,这就非常高级了。
这里的pagination和搜索使用到了nuqs这个库,useQueryState这个hook,将搜索条件和pagination相关参数放到了url上,然后从url上获取参数,然后触发更新。
这个案例是很复杂的,搞清楚了之后可以分享出来。
简单案例的实现步骤
table好做,直接照抄即可,tanstack/table里面第一个案例就做出来了:
生成的表格是没有样式的,还需要自己加样式:
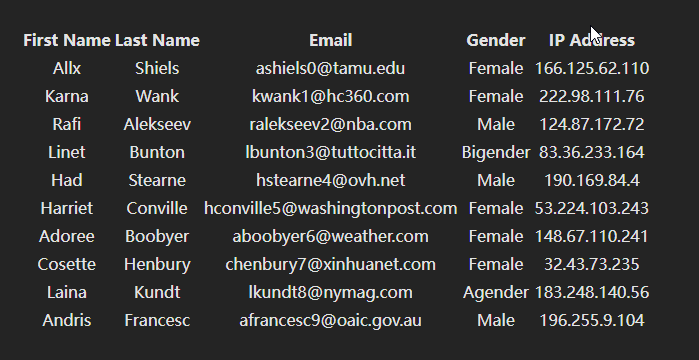
困难的是pagination应该怎么做?
TanStack Table 的分页功能分为两种主要模式:客户端分页 和 服务端分页。 你现在的项目用的是服务端分页(manualPagination: true),这也是实际项目中最常用的方式。下面用最直白的语言解释它的实现原理。核心概念:
表格自己不存数据 TanStack Table 只是一个“渲染引擎”,它不负责存数据,也不自己切页。 它只负责:
- 根据你给它的 data(当前页的数据)来渲染表格
- 根据你给它的 pageCount(总页数)来显示分页控件
- 当用户点“下一页”时,它会调用 onPaginationChange 通知你
分页状态由你自己管理 你需要用 React 的 state 来记录当前是第几页、每页几条:
xxxxxxxxxxconst [pagination, setPagination] = useState({pageIndex: 0, // 当前页,从 0 开始pageSize: 10 // 每页显示几条})点击翻页 → 触发 state 变化 → 重新请求数据
当用户点“下一页”时发生的事:
- 用户点击 → table.nextPage() 被调用
- table 内部把 pageIndex +1
- 调用 onPaginationChange(你设置的 setPagination)
- state 更新 → React 重新渲染组件
- useQuery 发现 queryKey 变了(因为包含了 pageIndex),自动重新请求后端
- 后端返回新的那一页数据 → 表格显示新内容
流程图(文字版):
xxxxxxxxxx用户点下一页↓table.nextPage()↓触发onPaginationChange → table内部setPagination(prev => prev + 1)↓React re-render↓useQuery 检测到 queryKey 变了(['skaters', search, {pageIndex:1, pageSize:10}])↓重新发请求 → http://localhost:3001/api/skaters?page=1&limit=10↓拿到新数据 → data.data 变成新的 10 条 → 表格更新
代码中关键的几行
xxxxxxxxxx// 1. 分页状态const [pagination, setPagination] = useState({ pageIndex: 0, pageSize: 10 });// 2. 告诉 Table:我们自己管理分页(手动模式)const table = useReactTable({ data: data?.data ?? [], // 只渲染当前页的数据 pageCount: data?.pageCount ?? -1, // 总页数从后端来(-1表示未知) state: { pagination, // 传入当前分页状态 }, onPaginationChange: setPagination, // 当用户翻页时,Table会调用这个更新状态 manualPagination: true, // 重要!告诉 Table:分页不是我管的 // ...});// 3. useQuery 监听分页变化useQuery({ queryKey: ['skaters', search, pagination], // pagination 变 → 自动重新请求 queryFn: () => fetchSkaters(/* 用 pagination.pageIndex +1 去请求 */),});客户端分页 vs 服务端分页 对比(快速记忆)
| 特性 | 客户端分页 (manualPagination: false) | 服务端分页 (manualPagination: true) |
|---|---|---|
| 数据从哪来 | 一次性把所有数据拿回来 | 每次只拿当前页的数据 |
| 适合场景 | 数据量很小(<1000条) | 数据量大、需要搜索、排序 |
| 性能 | 前端压力大,首次加载慢 | 后端承担分页逻辑,响应更快 |
| 实现难度 | 简单,Table 自动处理 | 需要自己管理 pageIndex 和请求 |
| 你现在用的 | 否 | 是(推荐) |
总结一句话“分页本质上就是:用户点翻页 → 更新 pageIndex → 带着新的页码重新请求后端 → 把后端返回的新数据塞给表格渲染” TanStack Table 只负责“通知你”和“渲染当前页”,真正的分页逻辑(切哪一页、请求哪一页)是你自己通过 state + useQuery 完成的。
看了案例之后,我发现不管是分页还是搜索,都是通过
useQuery里面的queryKey来触发的。将pageNum、pageSize、keyword、各种搜索词这些状态放进queryKey里面去,当这些状态变化的时候,就会触发请求数据。所以说react query真的解决了问题。
简单案例代码
就是code/real-project里面的TablePagination组件。这里就不粘贴了,代码还是比较多的。
简单案例的问题点
翻页时页面闪动
主要原因通常有 3 个:
- 数据请求期间,data 变为 undefined 或 null,表格瞬间渲染空数组 → 内容消失
- keepPreviousData 没开,导致旧数据被清空,新数据还没回来
- 组件重新渲染时,表格高度/布局跳动
第1和3都是写一些HTML+CSS,针对第二个,需要配置useQuery里面的placeholderData: keepPreviousData,在新数据回来前,保留旧数据,这样就不会在翻页的时候清空数据,新数据返回后重新渲染数据,造成很突兀的闪动情况。
同时也可以配置useQuery里面的gcTime和staleTime,让缓存数据存在的时间更长一些,显示起来就很快。
搜索框输入一个字母就会触发更新
①加防抖,编写一个防抖的hook。
xxxxxxxxxx// 1. 引入 useDebounce(自己写一个简单 hook 就行)import { useState, useEffect } from 'react';// 防抖 hookfunction useDebounce(value: string, delay: number = 400) { const [debouncedValue, setDebouncedValue] = useState(value); useEffect(() => { const timer = setTimeout(() => { setDebouncedValue(value); }, delay); return () => clearTimeout(timer); }, [value, delay]); return debouncedValue;}②使用防抖hook新建一个变量,这个变量改变了才触发更新。
xxxxxxxxxx// 2. 在组件中使用const [search, setSearch] = useState('');const debouncedSearch = useDebounce(search, 400); // 400ms 后才更新// useQuery 用 debouncedSearchuseQuery({ queryKey: ['skaters', debouncedSearch, pagination.pageIndex, pagination.pageSize], queryFn: () => fetchSkaters({ search: debouncedSearch, // 用防抖后的值 // ... }), placeholderData: keepPreviousData, // ...});// input 还是用原来的 search<input type="text" value={search} onChange={(e) => { setSearch(e.target.value); setPagination(prev => ({ prev, pageIndex: 0 })); // 也可以移到 debounced 里 }} placeholder="搜索姓名 / 邮箱..."/>搜索框输入后,无法获取到最新的输入结果,造成返回结果不正确
这个其实是我的问题,因为上一个问题中,useQuery的queryKey里面的search要改为debouncedSearch,我没有改,所以造成这个问题。改了之后就好了。
固定列宽
①在列定义中指定宽度
首先,在你的 columns 配置中为特定列添加 size 属性。TanStack Table 默认的 size 值是 150。
xxxxxxxxxxconst columns: ColumnDef<Skater>[] = [ { accessorKey: "order", header: "排序", size: 60, // 设置宽度 enableSorting: true }, { accessorKey: "name", header: "姓名", size: 150, }, { accessorKey: "email", header: "邮箱", size: 250, // 邮箱通常比较长,给大一点 }, // ... 其他列 { id: "actions", header: "操作", size: 120, // 固定操作列宽度 cell: ({ row }) => ( ) },];②在渲染时应用样式 (Tailwind)
TanStack Table 本身不负责渲染样式,你需要手动将 size 应用到 th 和 td 上。为了确保宽度严格固定,建议使用 table-fixed 布局。
- 修改表格标签:
给 table 加上 table-fixed 类。这会告诉浏览器不要根据内容自动撑开列宽,而是遵循你设置的宽度。
xxxxxxxxxx<table className="min-w-full divide-y divide-gray-200 table-fixed">- 修改单元格渲染:
在渲染 th 和 td 时,直接通过内联样式设置宽度:
xxxxxxxxxx{/* 在 thead 的 th 中 */}<th key={header.id} style={{ width: `${header.getSize()}px` }} // 获取上面定义的 size className="px-6 py-4 text-left ..."> {/* ... */}</th>{/* 在 tbody 的 td 中 */}<td key={cell.id} style={{ width: `${cell.column.getSize()}px` }} // 获取上面定义的 size className="px-6 py-4 whitespace-nowrap text-sm"> {flexRender(cell.column.columnDef.cell, cell.getContext())}</td>注意:
如果width不起作用,那么添加
min-width或者max-width,或者二者都添加。
溢出显示...,并且可以鼠标悬浮显示全部信息
①封装 OverflowTooltip 组件
这个组件会自动判断子元素是否溢出。如果是,则展示 Tooltip;如果不是,则只渲染原始文本。使用了shadcn的Tooltip组件。
xxxxxxxxxximport React, { useRef, useState } from "react"import { Tooltip, TooltipContent, TooltipProvider, TooltipTrigger,} from "@/components/ui/tooltip" // 确保路径正确interface OverflowTooltipProps { content: string children?: React.ReactNode}export const OverflowTooltip = ({ content }: OverflowTooltipProps) => { const [isOpen, setIsOpen] = useState(false) const [isOverflowing, setIsOverflowing] = useState(false) const textRef = useRef<HTMLDivElement>(null) const checkOverflow = () => { const element = textRef.current if (element) { // 判断内容宽度是否超过容器宽度 const overflowing = element.scrollWidth > element.clientWidth setIsOverflowing(overflowing) } } return ( <TooltipProvider> <Tooltip open={isOpen && isOverflowing} onOpenChange={(open) => setIsOpen(open)} > <TooltipTrigger asChild> <div ref={textRef} onMouseEnter={checkOverflow} className="truncate w-full cursor-default" > {content} </div> </TooltipTrigger> <TooltipContent side="top" className="max-w-[300px] break-all"> <p>{content}</p> </TooltipContent> </Tooltip> </TooltipProvider> )}②在 TanStack Table 的 columns 中应用
你可以直接在列定义的 cell 函数中使用该组件:
xxxxxxxxxxconst columns: ColumnDef<Skater>[] = [ // ... 其他列 { accessorKey: "email", header: "邮箱", size: 220, // 这里的宽度必须配合 table-fixed 才能触发溢出 cell: ({ getValue }) => { const email = getValue() as string return <OverflowTooltip content={email} /> }, }, { accessorKey: "name", header: "姓名", size: 150, cell: ({ getValue }) => { const name = getValue() as string return <OverflowTooltip content={name} /> }, },]③关键 CSS 配合(提醒)
为了确保溢出检测(scrollWidth > clientWidth)准确生效,请务必检查以下两点:
- 表格布局:在
<table>标签上必须有table-fixed。 - 单元格宽度:在
td渲染时,需要显式设置宽度:
xxxxxxxxxx<td key={cell.id} style={{ width: `${cell.column.getSize()}px` }} // 必须有固定宽度 className="px-6 py-4"> {flexRender(cell.column.columnDef.cell, cell.getContext())}</td>